User Guide#
Overview#
General Formulation of Dimensionality Reduction#
DR aims to construct a low-dimensional representation (or embedding) \(\mathbf{Z} = (\mathbf{z}_1, ..., \mathbf{z}_n)^\top\) of an input dataset \(\mathbf{X} = (\mathbf{x}_1, ..., \mathbf{x}_n)^\top\) that best preserves its geometry, encoded via a pairwise affinity matrix \(\mathbf{P}\). To this end, DR methods optimize \(\mathbf{Z}\) such that a pairwise affinity matrix in the embedding space (denoted \(\mathbf{Q}\)) matches \(\mathbf{P}\). This general problem is as follows
where \(\mathcal{L}\) is typically the \(\ell_2\) or cross-entropy loss.
TorchDR is structured around the above formulation \(\text{(DR)}\).
The input affinity \(\mathbf{P}\) is constructed using an Affinity object.
For the embedding affinity \(\mathbf{Q}\), TorchDR offers flexibility: it can be defined as a separate Affinity object or, more commonly, the embedding kernel is integrated directly into the loss function for efficiency.
All modules follow the sklearn [Pedregosa et al., 2011] API and can be used in sklearn pipelines.
GPU Support#
TorchDR is built on top of torch [Paszke et al., 2019], offering GPU support and automatic differentiation. To utilize GPU support, set device="cuda" when initializing any module; for CPU computations, set device="cpu". DR particularly benefits from GPU acceleration as most computations involve matrix reductions that are highly parallelizable.
The following sections cover the available DR methods, the affinity building blocks, and advanced scalability options.
Dimensionality Reduction Methods#
TorchDR provides a wide range of dimensionality reduction (DR) methods. All DR estimators inherit the structure of the DRModule() class:
Base class for dimensionality reduction methods. |
They are sklearn.base.BaseEstimator and sklearn.base.TransformerMixin classes which can be called with the fit_transform method.
Outside of Spectral Methods, a closed-form solution to the DR problem is typically not available. The problem can then be solved using gradient-based optimizers.
For users who want full control over both input and output affinities, the AffinityMatcher class provides a flexible base that accepts separate affinity_in and affinity_out objects.
Dimensionality reduction by matching two affinity matrices. |
In what follows we briefly present two families of DR algorithms: neighbor embedding methods and spectral methods.
Neighbor Embedding#
TorchDR aims to implement most popular neighbor embedding (NE) algorithms. In these methods, \(\mathbf{P}\) and \(\mathbf{Q}\) can be viewed as soft neighborhood graphs, hence the term neighbor embedding.
NE objectives share a common structure: they minimize a weighted sum of an attractive term and a repulsive term. The attractive term is often the cross-entropy between the input and output affinities, while the repulsive term is typically a function of the output affinities only. Thus, the NE problem can be formulated as:
In the above, \(\mathcal{L}_{\mathrm{rep}}(\mathbf{Q})\) represents the repulsive part of the loss function while \(\lambda\) is a hyperparameter that controls the balance between attraction and repulsion. The latter is called early_exaggeration_coeff in TorchDR because it is often set to a value larger than one at the beginning of the optimization.
Many NE methods can be represented within this framework. See below for some examples.
Method |
Repulsive term \(\mathcal{L}_{\mathrm{rep}}\) |
Input affinity \(\mathbf{P}\) |
Embedding kernel \(\mathbf{Q}\) |
|---|---|---|---|
\(\sum_{i} \log(\sum_j Q_{ij})\) |
\(Q_{ij} = \exp(- \| \mathbf{z}_i - \mathbf{z}_j \|^2)\) |
||
\(\log(\sum_{ij} Q_{ij})\) |
\(Q_{ij} = (1 + \| \mathbf{z}_i - \mathbf{z}_j \|^2)^{-1}\) |
||
\(\sum_{ij} Q_{ij}\) |
|||
\(\sum_i \log(\sum_{j \in \mathrm{Neg}(i)} Q_{ij})\) |
\(Q_{ij} = (1 + \| \mathbf{z}_i - \mathbf{z}_j \|^2)^{-1}\) |
||
\(- \sum_{i, j \in \mathrm{Neg}(i)} \log (1 - Q_{ij})\) |
\(Q_{ij} = (1 + a \| \mathbf{z}_i - \mathbf{z}_j \|^{2b})^{-1}\) |
||
\(- \sum_{i, j \in \mathrm{Neg}(i)} \log (1 - Q_{ij})\) |
\(Q_{ij} = (1 + \| \mathbf{z}_i - \mathbf{z}_j \|^2)^{-1}\) |
In the above table, \(\mathrm{Neg}(i)\) denotes the set of negative samples for point \(i\). They are usually sampled uniformly at random from the dataset.
Spectral Methods#
Spectral methods correspond to choosing the scalar product affinity \(P_{ij} = \langle \mathbf{z}_i, \mathbf{z}_j \rangle\) for the embeddings and the \(\ell_2\) loss.
When \(\mathbf{P}\) is positive semi-definite, this problem is commonly known as kernel Principal Component Analysis [Ham et al., 2004] and an optimal solution is given by
where \(\lambda_1, ..., \lambda_d\) are the largest eigenvalues of the centered kernel matrix \(\mathbf{P}\) and \(\mathbf{v}_1, ..., \mathbf{v}_d\) are the corresponding eigenvectors.
Note
PCA (available at torchdr.PCA) corresponds to choosing \(P_{ij} = \langle \mathbf{x}_i, \mathbf{x}_j \rangle\).
Affinities#
Affinities are the essential building blocks of dimensionality reduction methods. TorchDR provides a wide range of affinities. See API and Modules for a complete list.
Base structure#
Affinities inherit the structure of the following Affinity() class.
Base class for affinity matrices. |
If computations can be performed in log domain, the LogAffinity() class should be used.
Base class for affinity matrices in log domain. |
Affinities are objects that can directly be called. The outputted affinity matrix is a square matrix of size (n, n) where n is the number of input samples.
Here is an example with the NormalizedGaussianAffinity:
>>> import torch, torchdr
>>>
>>> n = 100
>>> data = torch.randn(n, 2)
>>> affinity = torchdr.NormalizedGaussianAffinity(normalization_dim=None)
>>> affinity_matrix = affinity(data)
>>> print(affinity_matrix.shape)
(100, 100)
Spotlight on affinities based on entropic projections#
A widely used family of affinities focuses on controlling the entropy of the affinity matrix. It is notably a crucial component of Neighbor-Embedding methods (see Neighbor Embedding).
These affinities are normalized such that each row sums to one, allowing the affinity matrix to be viewed as a Markov transition matrix. An adaptive bandwidth parameter then determines how the mass from each point spreads to its neighbors. The bandwidth is based on the perplexity hyperparameter which controls the number of effective neighbors for each point.
The resulting affinities can be viewed as a soft approximation of a k-nearest neighbor graph, where perplexity takes the role of k. This allows for capturing more nuances than binary weights, as closer neighbors receive a higher weight compared to those farther away. Ultimately, perplexity is an interpretable hyperparameter that governs the scale of dependencies represented in the affinity.
The following table outlines the aspects controlled by different formulations of entropic affinities. Marginal indicates whether each row of the affinity matrix has a controlled sum. Symmetry indicates whether the affinity matrix is symmetric. Entropy indicates whether each row of the affinity matrix has controlled entropy, dictated by the perplexity hyperparameter.
Affinity (associated DR method) |
Marginal |
Symmetry |
Entropy |
|---|---|---|---|
✅ |
❌ |
❌ |
|
✅ |
✅ |
❌ |
|
✅ |
❌ |
✅ |
|
✅ |
✅ |
✅ |
More details on these affinities can be found in the SNEkhorn paper [Van Assel et al., 2024].
Examples using EntropicAffinity:#
Entropic Affinities can adapt to varying noise levels

Neighbor Embedding on genomics & equivalent affinity matcher formulation
Other various affinities#
TorchDR features other affinities that can be used in various contexts.
For instance, the UMAP [McInnes et al., 2018] algorithm relies on the affinity UMAPAffinity in input space.
UMAPAffinity follows a similar construction as entropic affinities to ensure a constant number of effective neighbors, with n_neighbors playing the role of the perplexity hyperparameter.
Another example is the doubly stochastic normalization of a base affinity under the \(\ell_2\) geometry that has recently been proposed for DR [Zhang et al., 2023]. This method is analogous to SinkhornAffinity where the Shannon entropy is replaced by the \(\ell_2\) norm to recover a sparse affinity.
It is available at DoublyStochasticQuadraticAffinity.
Scalability & Backends#
For large datasets, TorchDR provides several features to scale computations.
Handling the quadratic cost via sparsity or symbolic tensors#
Affinities naturally incur a quadratic memory cost, which can be particularly problematic when dealing with large numbers of samples, especially when using GPUs.
Many affinity metrics only require computing distances to each point’s k nearest neighbors.
For large datasets (typically when \(n > 10^4\)) where the full pairwise-distance matrix won’t fit in GPU memory,
TorchDR can offload these computations to the GPU-compatible kNN library Faiss.
Simply set backend to faiss to leverage Faiss’s efficient implementations.
Alternatively, for exact computations or affinities that can’t be limited to kNNs, you can use symbolic (lazy) tensors to avoid memory overflows.
TorchDR integrates with pykeops[Charlier et al., 2021], representing tensors as mathematical expressions evaluated directly on your data samples.
By computing on-the-fly formulas instead of storing full matrices, this approach removes memory constraints entirely.
However, for very large datasets (typically when \(n > 10^5\)), the computational cost becomes prohibitive.
Simply set backend to keops in any module to enable it.

The above figure is taken from here.
{kind=link}
Multi-GPU distributed training#
For very large datasets, TorchDR supports multi-GPU distributed training to parallelize computations across multiple GPUs. This is particularly useful when the affinity matrix is too large to compute on a single GPU or when faster computation is needed.
How it works:
Data partitioning: The full dataset \(\mathbf{X} \in \mathbb{R}^{N \times d}\) is split into chunks across GPUs. Each GPU handles a subset of \(n_i\) samples.
Shared neighbor index: A FAISS index is built on the full dataset and shared across all GPUs, enabling efficient k-nearest neighbor queries.
Parallel affinity computation: Each GPU computes the affinity rows for its chunk by querying the shared index. GPU \(i\) computes rows \([\text{start}_i, \text{end}_i)\) of the affinity matrix.
Distributed gradient computation: During optimization, each GPU:
Computes gradients \(\nabla \mathcal{L}_i\) for its local chunk
Maintains a full copy of the embedding \(\mathbf{Z} \in \mathbb{R}^{N \times q}\)
Synchronizes gradients via all-reduce across GPUs
Synchronized updates: After all-reduce, each GPU has identical aggregated gradients and applies the same optimizer step, keeping embeddings synchronized.
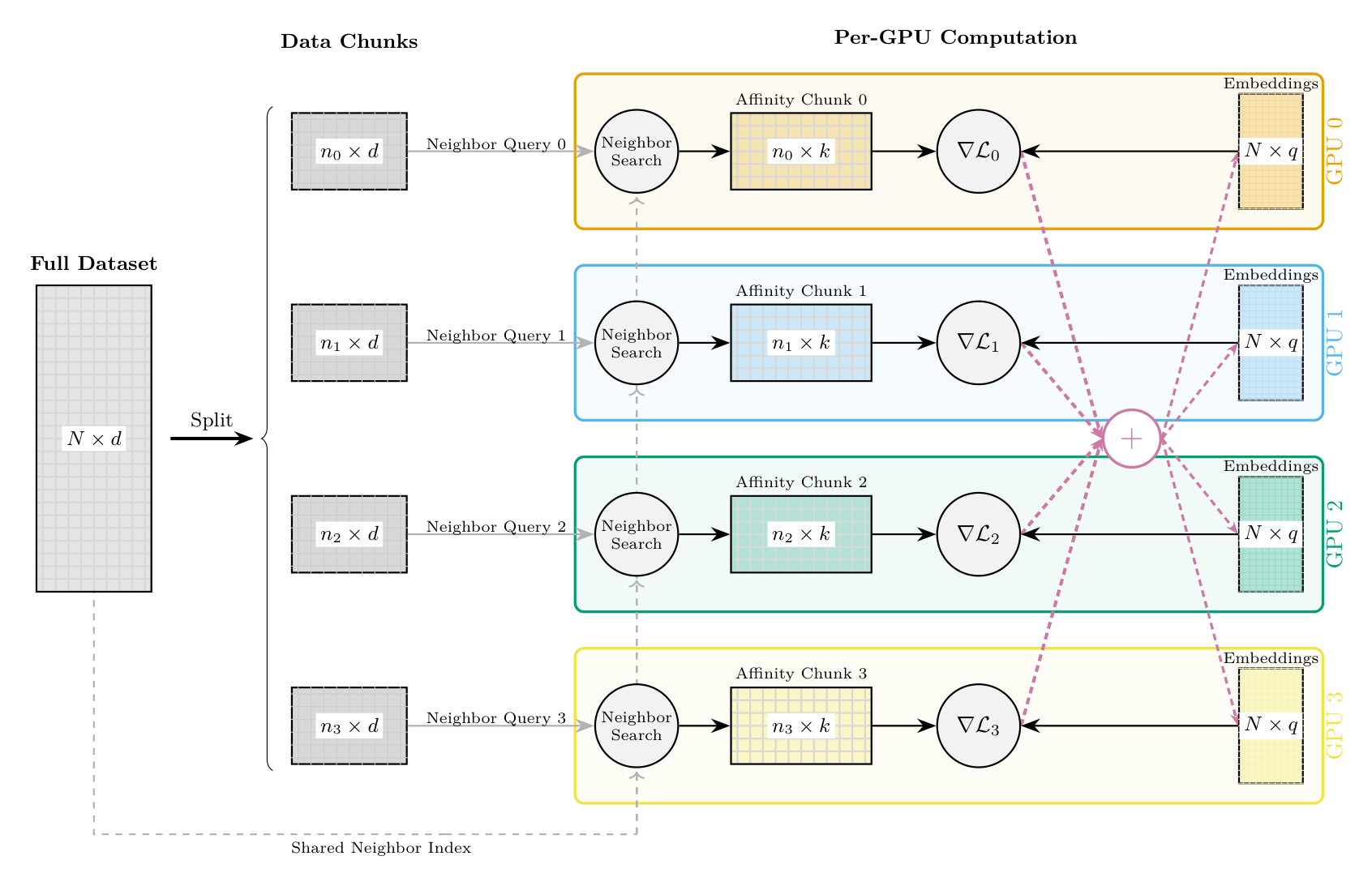
Multi-GPU dimensionality reduction pipeline. The dataset is split into chunks across GPUs. Each GPU performs neighbor search using a shared index, computes its affinity chunk, and generates local gradients. Gradients are synchronized via all-reduce and used to update the embedding copies maintained on each device.
Usage:
Multi-GPU mode is enabled automatically when launching with torchrun or the TorchDR CLI:
# Using the TorchDR CLI (recommended)
torchdr --gpus 4 your_script.py
# Or using torchrun directly
torchrun --nproc_per_node=4 your_script.py
In your script, simply use TorchDR as usual:
import torchdr
# Distributed mode is auto-detected when launched with torchrun
model = torchdr.UMAP(n_neighbors=15, verbose=True)
embedding = model.fit_transform(X)
Requirements:
backend="faiss"(default for most methods)Multiple CUDA GPUs available
Launch with
torchdrCLI ortorchrun
Supported methods:
Currently, the following methods support multi-GPU:
DataLoader for Streaming Data#
For datasets too large to fit in RAM, TorchDR supports passing a PyTorch DataLoader directly to fit_transform instead of a tensor. This enables streaming computation where data is processed batch-by-batch.
How it works:
Incremental index building: The FAISS index is built incrementally from batches
Batch-by-batch k-NN queries: Neighbor queries are performed as each batch arrives
Automatic PCA initialization: When
init="pca",IncrementalPCAis used automatically
Usage:
from torch.utils.data import DataLoader, TensorDataset
import torchdr
dataset = TensorDataset(X) # X is your large tensor
dataloader = DataLoader(dataset, batch_size=10000)
model = torchdr.UMAP(n_neighbors=15, backend="faiss")
embedding = model.fit_transform(dataloader)
Requirements:
backend="faiss"must be usedThe DataLoader must yield tensors (or tuples where the first element is the data tensor)