TSNE#
- class torchdr.TSNE(perplexity: float = 30, n_components: int = 2, lr: float | str = 'auto', optimizer: str | Type[Optimizer] = 'SGD', optimizer_kwargs: Dict | str = 'auto', scheduler: str | Type[LRScheduler] | None = None, scheduler_kwargs: Dict | None = None, init: str = 'pca', init_scaling: float = 0.0001, min_grad_norm: float = 1e-07, max_iter: int = 2000, device: str = 'auto', backend: str | FaissConfig | None = None, verbose: bool = False, random_state: float | None = None, early_exaggeration_coeff: float = 12.0, early_exaggeration_iter: int = 250, max_iter_affinity: int = 100, metric: str = 'sqeuclidean', sparsity: bool = True, check_interval: int = 50, compile: bool = False, **kwargs)[source]#
Bases:
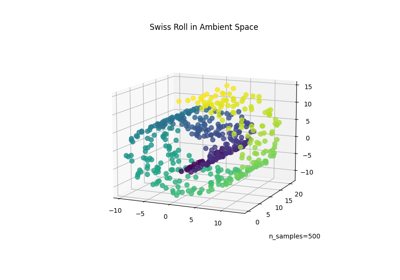
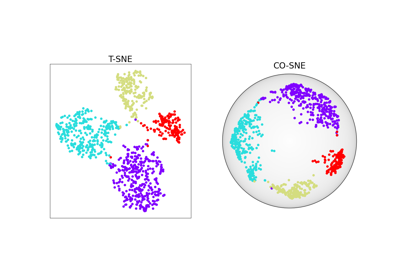
SparseNeighborEmbeddingt-Stochastic Neighbor Embedding (t-SNE) introduced in [Van der Maaten and Hinton, 2008].
It uses a
EntropicAffinityas input affinity \(\mathbf{P}\) and a Student-t kernel as output affinity \(Q_{ij} = (1 + \| \mathbf{z}_i - \mathbf{z}_j \|^2)^{-1}\).The loss function is defined as:
\[-\sum_{ij} P_{ij} \log Q_{ij} + \log \Big( \sum_{ij} Q_{ij} \Big) \:.\]- Parameters:
perplexity (float) – Number of ‘effective’ nearest neighbors. Consider selecting a value between 2 and the number of samples. Different values can result in significantly different results.
n_components (int, optional) – Dimension of the embedding space.
lr (float or 'auto', optional) – Learning rate for the algorithm, by default ‘auto’.
optimizer (str or torch.optim.Optimizer, optional) – Name of an optimizer from torch.optim or an optimizer class. Default is “SGD”.
optimizer_kwargs (dict or 'auto', optional) – Additional keyword arguments for the optimizer. Default is ‘auto’, which sets appropriate momentum values for SGD based on early exaggeration phase.
scheduler (str or torch.optim.lr_scheduler.LRScheduler, optional) – Name of a scheduler from torch.optim.lr_scheduler or a scheduler class. Default is None (no scheduler).
scheduler_kwargs (dict, optional) – Additional keyword arguments for the scheduler.
init ({'normal', 'pca'} or torch.Tensor of shape (n_samples, output_dim), optional) – Initialization for the embedding Z, default ‘pca’.
init_scaling (float, optional) – Scaling factor for the initialization, by default 1e-4.
min_grad_norm (float, optional) – Precision threshold at which the algorithm stops, by default 1e-7.
max_iter (int, optional) – Number of maximum iterations for the descent algorithm, by default 2000.
device (str, optional) – Device to use, by default “auto”.
backend ({"keops", "faiss", None} or FaissConfig, optional) – Which backend to use for handling sparsity and memory efficiency. Can be: - “keops”: Use KeOps for memory-efficient symbolic computations - “faiss”: Use FAISS for fast k-NN computations with default settings - None: Use standard PyTorch operations - FaissConfig object: Use FAISS with custom configuration Default is None.
verbose (bool, optional) – Verbosity, by default False.
random_state (float, optional) – Random seed for reproducibility, by default None.
early_exaggeration_coeff (float, optional) – Coefficient for the attraction term during the early exaggeration phase. By default 12.0 for early exaggeration.
early_exaggeration_iter (int, optional) – Number of iterations for early exaggeration, by default 250.
max_iter_affinity (int, optional) – Number of maximum iterations for the entropic affinity root search.
metric ({'sqeuclidean', 'manhattan'}, optional) – Metric to use for the input affinity, by default ‘sqeuclidean’.
sparsity (bool, optional) – Whether to use sparsity mode for the input affinity. Default is True.
check_interval (int, optional) – Interval for checking the convergence of the algorithm, by default 50.
compile (bool, optional) – Whether to compile the algorithm using torch.compile. Default is False.
Examples using TSNE:#

Neighbor Embedding on genomics & equivalent affinity matcher formulation